其实这说来也很好实现。只要我们在查询的过程中,把沿途的每个节点的父节点都设为根节点即可。下一次再查询时,我们就可以省很多事。这用递归的写法很容易实现:
合并(路径压缩)
int find(int x){
if(x == fa[x])
return x;
else{
fa[x] = find(fa[x]); //父节点设为根节点
return fa[x]; //返回父节点 }}路径压缩优化后,并查集的时间复杂度已经比较低了,绝大多数不相交集合的合并查询问题都能够解决。然而,对于某些时间卡得很紧的题目,我们还可以进一步优化。
按秩合并
有些人可能有一个误解,以为路径压缩优化后,并查集始终都是一个菊花图(只有两层的树的俗称)。但其实,由于路径压缩只在查询时进行,也只压缩一条路径,所以并查集最终的结构仍然可能是比较复杂的。例如,现在我们有一棵较复杂的树需要与一个单元素的集合合并:
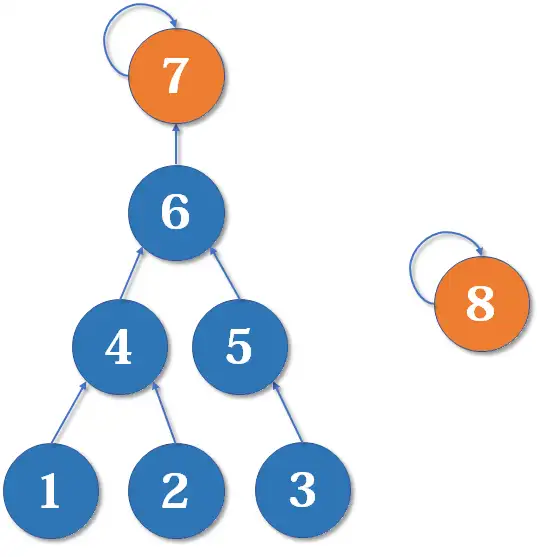
假如这时我们要merge(7,8),如果我们可以选择的话,是把7的父节点设为8好,还是把8的父节点设为7好呢?
当然是后者。因为如果把7的父节点设为8,会使树的深度(树中最长链的长度)加深,原来的树中每个元素到根节点的距离都变长了,之后我们寻找根节点的路径也就会相应变长。虽然我们有路径压缩,但路径压缩也是会消耗时间的。而把8的父节点设为7,则不会有这个问题,因为它没有影响到不相关的节点。
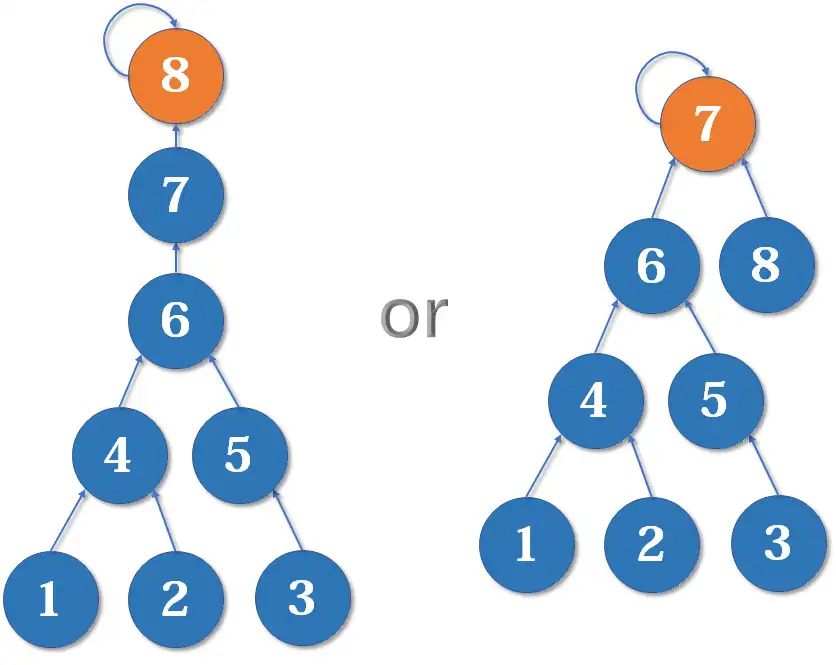
这启发我们:我们应该把简单的树往复杂的树上合并,而不是相反。因为这样合并后,到根节点距离变长的节点个数比较少。
我们用一个数组rank[]记录每个根节点对应的树的深度(如果不是根节点,其rank相当于以它作为根节点的子树的深度)。一开始,把所有元素的rank(秩)设为1。合并时比较两个根节点,把rank较小者往较大者上合并。
初始化(按秩合并)
inline void init(int n){
for (int i = 1; i <= n; ++i)
{
fa[i] = i;
rank[i] = 1;
}}合并(按秩合并)
inline void merge(int i, int j){
int x = find(i), y = find(j); //先找到两个根节点 if (rank[x] <= rank[y])
fa[x] = y;
else
fa[y] = x;
if (rank[x] == rank[y] && x != y)
rank[y]++; //如果深度相同且根节点不同,则新的根节点的深度+1}为什么深度相同,新的根节点深度要+1?如下图,我们有两个深度均为2的树,现在要merge(2,5):
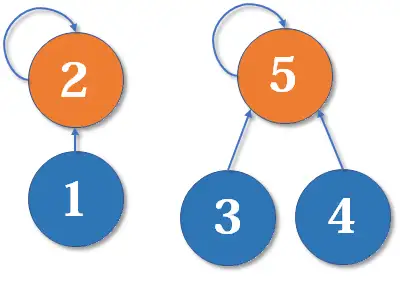
这里把2的父节点设为5,或者把5的父节点设为2,其实没有太大区别。我们选择前者,于是变成这样:
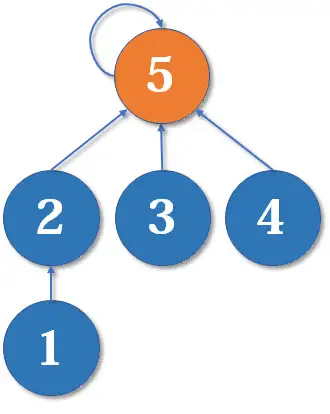
显然树的深度增加了1。另一种合并方式同样会让树的深度+1。